第四章:特殊資料結構¶
在之前的章節裡,我們討論了列表,Lisp 最多功能的資料結構。本章將示範如何使用 Lisp 其它的資料結構:陣列(包含向量與字串),結構以及雜湊表。它們或許不像列表這麼靈活,但存取速度更快並使用了更少空間。
Common Lisp 還有另一種資料結構:實體(instance)。實體將在 11 章討論,講述 CLOS。
4.1 陣列 (Array)¶
在 Common Lisp 裡,你可以呼叫 make-array 來構造一個陣列,第一個實參爲一個指定陣列維度的列表。要構造一個 2 x 3 的陣列,我們可以:
> (setf arr (make-array '(2 3) :initial-element nil))
#<Simple-Array T (2 3) BFC4FE>
Common Lisp 的陣列至少可以有七個維度,每個維度至多可以有 1023 個元素。
:initial-element 實參是選擇性的。如果有提供這個實參,整個陣列會用這個值作爲初始值。若試著取出未初始化的陣列內的元素,其結果爲未定義(undefined)。
用 aref 取出陣列內的元素。與 Common Lisp 的存取函數一樣, aref 是零索引的(zero-indexed):
> (aref arr 0 0)
NIL
要替換陣列的某個元素,我們使用 setf 與 aref :
> (setf (aref arr 0 0) 'b)
B
> (aref arr 0 0)
B
要表示字面常數的陣列(literal array),使用 #na 語法,其中 n 是陣列的維度。舉例來說,我們可以這樣表示 arr 這個陣列:
#2a((b nil nil) (nil nil nil))
如果全局變數 *print-array* 爲真,則陣列會用以下形式來顯示:
> (setf *print-array* t)
T
> arr
#2A((B NIL NIL) (NIL NIL NIL))
如果我們只想要一維的陣列,你可以給 make-array 第一個實參傳一個整數,而不是一個列表:
> (setf vec (make-array 4 :initial-element nil))
#(NIL NIL NIL NIL)
一維陣列又稱爲向量(vector)。你可以通過呼叫 vector 來一步驟構造及填滿向量,向量的元素可以是任何型別:
> (vector "a" 'b 3)
#("a" b 3)
字面常數的陣列可以表示成 #na ,字面常數的向量也可以用這種語法表達。
可以用 aref 來存取向量,但有一個更快的函數叫做 svref ,專門用來存取向量。
> (svref vec 0)
NIL
在 svref 內的 “sv” 代表“簡單向量”(“simple vector”),所有的向量預設是簡單向量。 [1]
4.2 範例:二元搜索 (Example: Binary Search)¶
作爲一個範例,這小節示範如何寫一個在排序好的向量裡搜索物件的函數。如果我們知道一個向量是排序好的,我們可以比(65頁) find 做的更好, find 必須依序檢視每一個元素。我們可以直接跳到向量中間開始找。如果中間的元素是我們要找的物件,搜索完畢。要不然我們持續往左半部或往右半部搜索,取決於物件是小於或大於中間的元素。
圖 4.1 包含了一個這麼工作的函數。其實這兩個函數: bin-search 設置初始範圍及發送控制信號給 finder , finder 尋找向量 vec 內 obj 是否介於 start 及 end 之間。
(defun bin-search (obj vec)
(let ((len (length vec)))
(and (not (zerop len))
(finder obj vec 0 (- len 1)))))
(defun finder (obj vec start end)
(let ((range (- end start)))
(if (zerop range)
(if (eql obj (aref vec start))
obj
nil)
(let ((mid (+ start (round (/ range 2)))))
(let ((obj2 (aref vec mid)))
(if (< obj obj2)
(finder obj vec start (- mid 1))
(if (> obj obj2)
(finder obj vec (+ mid 1) end)
obj)))))))
圖 4.1: 搜索一個排序好的向量
如果要找的 range 縮小至一個元素,而如果這個元素是 obj 的話,則 finder 直接返回這個元素,反之返回 nil 。如果 range 大於 1 ,我們設置 middle ( round 返回離實參最近的整數) 為 obj2 。如果 obj 小於 obj2 ,則遞迴地往向量的左半部尋找。如果 obj 大於 obj2 ,則遞迴地往向量的右半部尋找。剩下的一個選擇是 obj=obj2 ,在這個情況我們找到要找的元素,直接返回這個元素。
如果我們插入下面這行至 finder 的起始處:
(format t "~A~%" (subseq vec start (+ end 1)))
我們可以觀察被搜索的元素的數量,是每一步往左減半的:
> (bin-search 3 #(0 1 2 3 4 5 6 7 8 9))
#(0 1 2 3 4 5 6 7 8 9)
#(0 1 2 3)
#(3)
3
4.3 字元與字串 (Strings and Characters)¶
字串是字元組成的向量。我們用一系列由雙引號包住的字元,來表示一個字串常數,而字元 c 用 #\c 表示。
每個字元都有一個相關的整數 ── 通常是 ASCII 碼,但不一定是。在多數的 Lisp 實現裡,函數 char-code 返回與字元相關的數字,而 code-char 返回與數字相關的字元。
字元比較函數 char< (小於), char<= (小於等於), char= (等於), char>= (大於等於) , char> (大於),以及 char/= (不同)。他們的工作方式和 146 頁(譯註 9.3 節)比較數字用的運算子一樣。
> (sort "elbow" #'char<)
"below"
由於字串是字元向量,序列與陣列的函數都可以用在字串。你可以用 aref 來取出元素,舉例來說,
> (aref "abc" 1)
#\b
但針對字串可以使用更快的 char 函數:
> (char "abc" 1)
#\b
可以使用 setf 搭配 char (或 aref )來替換字串的元素:
> (let ((str (copy-seq "Merlin")))
(setf (char str 3) #\k)
str)
如果你想要比較兩個字串,你可以使用通用的 equal 函數,但還有一個比較函數,是忽略字母大小寫的 string-equal :
> (equal "fred" "fred")
T
> (equal "fred" "Fred")
NIL
>(string-equal "fred" "Fred")
T
Common Lisp 提供大量的操控、比較字串的函數。收錄在附錄 D,從 364 頁開始。
有許多方式可以創建字串。最普遍的方式是使用 format 。將第一個參數設爲 nil 來呼叫 format ,使它返回一個原本會印出來的字串:
> (format nil "~A or ~A" "truth" "dare")
"truth or dare"
但若你只想把數個字串連結起來,你可以使用 concatenate ,它接受一個特定型別的符號,加上一個或多個序列:
> (concatenate 'string "not " "to worry")
"not to worry"
4.4 序列 (Sequences)¶
在 Common Lisp 裡,序列型別包含了列表與向量(因此也包含了字串)。有些用在列表的函數,實際上是序列函數,包括 remove 、 length 、 subseq 、 reverse 、 sort 、 every 以及 some 。所以 46 頁(譯註 3.11 小節的 mirror? 函數)我們所寫的函數,也可以用在別種序列上:
> (mirror? "abba")
T
我們已經看過四種用來取出序列元素的函數: 給列表使用的 nth , 給向量使用的 aref 及 svref ,以及給字串使用的 char 。 Common Lisp 也提供了通用的 elt ,對任何種類的序列都有效:
> (elt '(a b c) 1)
B
針對特定型別的序列,特定的存取函數會比較快,所以使用 elt 是沒有意義的,除非在程式當中,有需要支援通用序列的地方。
使用 elt ,我們可以寫一個針對向量來說更有效率的 mirror? 版本:
(defun mirror? (s)
(let ((len (length s)))
(and (evenp len)
(do ((forward 0 (+ forward 1))
(back (- len 1) (- back 1)))
((or (> forward back)
(not (eql (elt s forward)
(elt s back))))
(> forward back))))))
這個版本也可用在列表,但這個實現更適合給向量使用。頻繁的對列表呼叫 elt 的代價是昂貴的,因爲列表僅允許循序存取。而向量允許隨機存取,從任何元素來存取每一個元素都是廉價的。
許多序列函數接受一個或多個,由下表所列的標準關鍵字參數:
| 參數 | 用途 | 預設值 |
|---|---|---|
| :key | 應用至每個元素的函數 | identity |
| :test | 作來比較的函數 | eql |
| :from-end | 若爲真,反向工作。 | nil |
| :start | 起始位置 | 0 |
| :end | 若有給定,結束位置。 | nil |
一個接受所有關鍵字參數的函數是 position ,返回序列中一個元素的位置,未找到元素時則返回 nil 。我們使用 position 來示範關鍵字參數所扮演的角色。
> (position #\a "fantasia")
1
> (position #\a "fantasia" :start 3 :end 5)
4
第二個例子我們要找在第四個與第六個字元間,第一個 a 所出現的位置。 :start 關鍵字參數是第一個被考慮的元素位置,預設是序列的第一個元素。 :end 關鍵字參數,如果有給的話,是第一個不被考慮的元素位置。
如果我們給入 :from-end 關鍵字參數,
> (position #\a "fantasia" :from-end t)
7
我們得到最靠近結尾的 a 的位置。但位置是像平常那樣計算;而不是從尾端算回來的距離。
:key 關鍵字參數是序列中每個元素在被考慮之前,應用至元素上的函數。如果我們說,
> (position 'a '((c d) (a b)) :key #'car)
1
那麼我們要找的是,元素的 car 部分是符號 a 的第一個元素。
:test 關鍵字參數接受需要兩個實參的函數,並定義了怎樣是一個成功的匹配。預設函數爲 eql 。如果你想要匹配一個列表,你也許想使用 equal 來取代:
> (position '(a b) '((a b) (c d)))
NIL
> (position '(a b) '((a b) (c d)) :test #'equal)
0
:test 關鍵字參數可以是任何接受兩個實參的函數。舉例來說,給定 < ,我們可以詢問第一個使第一個參數比它小的元素位置:
> (position 3 '(1 0 7 5) :test #'<)
2
使用 subseq 與 position ,我們可以寫出分開序列的函數。舉例來說,這個函數
(defun second-word (str)
(let ((p1 (+ (position #\ str) 1)))
(subseq str p1 (position #\ str :start p1))))
返回字串中第一個單字空格後的第二個單字:
> (second-word "Form follows function")
"follows"
要找到滿足謂詞的元素,其中謂詞接受一個實參,我們使用 position-if 。它接受一個函數與序列,並返回第一個滿足此函數的元素:
> (position-if #'oddp '(2 3 4 5))
1
position-if 接受除了 :test 之外的所有關鍵字參數。
有許多相似的函數,如給序列使用的 member 與 member-if 。分別是, find (接受全部關鍵字參數)與 find-if (接受除了 :test 之外的所有關鍵字參數):
> (find #\a "cat")
#\a
> (find-if #'characterp "ham")
#\h
不同於 member 與 member-if ,它們僅返回要尋找的物件。
通常一個 find-if 的呼叫,如果解讀爲 find 搭配一個 :key 關鍵字參數的話,會顯得更清楚。舉例來說,表達式
(find-if #'(lambda (x)
(eql (car x) 'complete))
lst)
可以更好的解讀爲
(find 'complete lst :key #'car)
函數 remove (22 頁)以及 remove-if 通常都可以用在序列。它們跟 find 與 find-if 是一樣的關係。另一個相關的函數是 remove-duplicates ,僅保留序列中每個元素的最後一次出現。
> (remove-duplicates "abracadabra")
"cdbra"
這個函數接受前表所列的所有關鍵字參數。
函數 reduce 用來把序列壓縮成一個值。它至少接受兩個參數,一個函數與序列。函數必須是接受兩個實參的函數。在最簡單的情況下,一開始函數用序列前兩個元素作爲實參來呼叫,之後接續的元素作爲下次呼叫的第二個實參,而上次返回的值作爲下次呼叫的第一個實參。最後呼叫最終返回的值作爲 reduce 整個函數的返回值。也就是說像是這樣的表達式:
(reduce #'fn '(a b c d))
等同於
(fn (fn (fn 'a 'b) 'c) 'd)
我們可以使用 reduce 來擴充只接受兩個參數的函數。舉例來說,要得到三個或多個列表的交集(intersection),我們可以:
> (reduce #'intersection '((b r a d 's) (b a d) (c a t)))
(A)
4.5 範例:解析日期 (Example: Parsing Dates)¶
作爲序列操作的範例,本節示範了如何寫程式來解析日期。我們將編寫一個程式,可以接受像是 “16 Aug 1980” 的字串,然後返回一個表示日、月、年的整數列表。
(defun tokens (str test start)
(let ((p1 (position-if test str :start start)))
(if p1
(let ((p2 (position-if #'(lambda (c)
(not (funcall test c)))
str :start p1)))
(cons (subseq str p1 p2)
(if p2
(tokens str test p2)
nil)))
nil)))
(defun constituent (c)
(and (graphic-char-p c)
(not (char= c #\ ))))
圖 4.2 辨別符號 (token)
圖 4.2 裡包含了某些在這個應用裡所需的通用解析函數。第一個函數 tokens ,用來從字串中取出語元 (token)。給定一個字串及測試函數,滿足測試函數的字元組成子字串,子字串再組成列表返回。舉例來說,如果測試函數是對字母返回真的 alpha-char-p 函數,我們得到:
> (tokens "ab12 3cde.f" #'alpha-char-p 0)
("ab" "cde" "f")
所有不滿足此函數的字元被視爲空白 ── 他們是語元的分隔符,但永遠不是語元的一部分。
函數 constituent 被定義成用來作爲 tokens 的實參。
在 Common Lisp 裡,圖形字元是我們可見的字元,加上空白字元。所以如果我們用 constituent 作爲測試函數時,
> (tokens "ab12 3cde.f gh" #'constituent 0)
("ab12" "3cde.f" "gh")
則語元將會由空白區分出來。
圖 4.3 包含了特別爲解析日期打造的函數。函數 parse-date 接受一個特別形式組成的日期,並返回代表這個日期的整數列表:
> (parse-date "16 Aug 1980")
(16 8 1980)
(defun parse-date (str)
(let ((toks (tokens str #'constituent 0)))
(list (parse-integer (first toks))
(parse-month (second toks))
(parse-integer (third toks)))))
(defconstant month-names
#("jan" "feb" "mar" "apr" "may" "jun"
"jul" "aug" "sep" "oct" "nov" "dec"))
(defun parse-month (str)
(let ((p (position str month-names
:test #'string-equal)))
(if p
(+ p 1)
nil)))
圖 4.3 解析日期的函數
parse-date 使用 tokens 來解析日期字串,接著呼叫 parse-month 及 parse-integer 來轉譯年、月、日。要找到月份,呼叫 parse-month ,由於使用的是 string-equal 來匹配月份的名字,所以輸入可以不分大小寫。要找到年和日,呼叫內建的 parse-integer , parse-integer 接受一個字串並返回對應的整數。
如果需要自己寫程式來解析整數,也許可以這麼寫:
(defun read-integer (str)
(if (every #'digit-char-p str)
(let ((accum 0))
(dotimes (pos (length str))
(setf accum (+ (* accum 10)
(digit-char-p (char str pos)))))
accum)
nil))
這個定義示範了在 Common Lisp 中,字元是如何轉成數字的 ── 函數 digit-char-p 不僅測試字元是否爲數字,同時返回了對應的整數。
4.6 結構 (Structures)¶
結構可以想成是豪華版的向量。假設你要寫一個程式來追蹤長方體。你可能會想用三個向量元素來表示長方體:高度、寬度及深度。與其使用原本的 svref ,不如定義像是下面這樣的抽象,程式會變得更容易閱讀,
(defun block-height (b) (svref b 0))
而結構可以想成是,這些函數通通都替你定義好了的向量。
要想定義結構,使用 defstruct 。在最簡單的情況下,只要給出結構及欄位的名字便可以了:
(defstruct point
x
y)
這裡定義了一個 point 結構,具有兩個欄位 x 與 y 。同時隱式地定義了 make-point 、 point-p 、 copy-point 、 point-x 及 point-y 函數。
2.3 節提過, Lisp 程式可以寫出 Lisp 程式。這是目前所見的明顯例子之一。當你呼叫 defstruct 時,它自動生成了其它幾個函數的定義。有了宏以後,你將可以自己來辦到同樣的事情(如果需要的話,你甚至可以自己寫出 defstruct )。
每一個 make-point 的呼叫,會返回一個新的 point 。可以通過給予對應的關鍵字參數,來指定單一欄位的值:
(setf p (make-point :x 0 :y 0))
#S(POINT X 0 Y 0)
存取 point 欄位的函數不僅被定義成可取出數值,也可以搭配 setf 一起使用。
> (point-x p)
0
> (setf (point-y p) 2)
2
> p
#S(POINT X 0 Y 2)
定義結構也定義了以結構爲名的型別。每個點的型別層級會是,型別 point ,接著是型別 structure ,再來是型別 atom ,最後是 t 型別。所以使用 point-p 來測試某個東西是不是一個點時,也可以使用通用性的函數,像是 typep 來測試。
> (point-p p)
T
> (typep p 'point)
T
我們可以在本來的定義中,附上一個列表,含有欄位名及預設表達式,來指定結構欄位的預設值。
(defstruct polemic
(type (progn
(format t "What kind of polemic was it? ")
(read)))
(effect nil))
如果 make-polemic 呼叫沒有給欄位指定初始值,則欄位會被設成預設表達式的值:
> (make-polemic)
What kind of polemic was it? scathing
#S(POLEMIC :TYPE SCATHING :EFFECT NIL)
結構顯示的方式也可以控制,以及結構自動產生的存取函數的字首。以下是做了前述兩件事的 point 定義:
(defstruct (point (:conc-name p)
(:print-function print-point))
(x 0)
(y 0))
(defun print-point (p stream depth)
(format stream "#<~A, ~A>" (px p) (py p)))
:conc-name 關鍵字參數指定了要放在欄位前面的名字,並用這個名字來生成存取函數。預設是 point- ;現在變成只有 p 。不使用預設的方式使程式的可讀性些微降低了,只有在需要常常用到這些存取函數時,你才會想取個短點的名字。
:print-function 是在需要顯示結構出來看時,指定用來打印結構的函數 ── 需要顯示的情況比如,要在頂層顯示時。這個函數需要接受三個實參:要被印出的結構,在哪裡被印出,第三個參數通常可以忽略。 [2] 我們會在 7.1 節討論流(stream)。現在來說,只要知道流可以作爲參數傳給 format 就好了。
函數 print-point 會用縮寫的形式來顯示點:
> (make-point)
#<0,0>
4.7 範例:二元搜索樹 (Example: Binary Search Tree)¶
由於 sort 本身系統就有了,極少需要在 Common Lisp 裡編寫排序程式。本節將示範如何解決一個與此相關的問題,這個問題尚未有現成的解決方案:維護一個已排序的物件集合。本節的程式會把物件存在二元搜索樹裡( binary search tree )或稱作 BST。當二元搜索樹平衡時,允許我們可以在與時間成 log n 比例的時間內,來尋找、添加或是刪除元素,其中 n 是集合的大小。
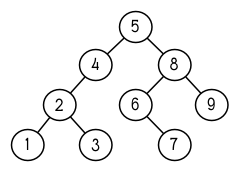
圖 4.4: 二元搜索樹
二元搜索樹是一種二元樹,給定某個排序函數,比如 < ,每個元素的左子樹都 < 該元素,而該元素 < 其右子樹。圖 4.4 展示了根據 < 排序的二元樹。
圖 4.5 包含了二元搜索樹的插入與尋找的函數。基本的資料結構會是 node (節點),節點有三個部分:一個欄位表示存在該節點的物件,以及各一個欄位表示節點的左子樹及右子樹。可以把節點想成是有一個 car 和兩個 cdr 的一個 cons 核(cons cell)。
(defstruct (node (:print-function
(lambda (n s d)
(format s "#<~A>" (node-elt n)))))
elt (l nil) (r nil))
(defun bst-insert (obj bst <)
(if (null bst)
(make-node :elt obj)
(let ((elt (node-elt bst)))
(if (eql obj elt)
bst
(if (funcall < obj elt)
(make-node
:elt elt
:l (bst-insert obj (node-l bst) <)
:r (node-r bst))
(make-node
:elt elt
:r (bst-insert obj (node-r bst) <)
:l (node-l bst)))))))
(defun bst-find (obj bst <)
(if (null bst)
nil
(let ((elt (node-elt bst)))
(if (eql obj elt)
bst
(if (funcall < obj elt)
(bst-find obj (node-l bst) <)
(bst-find obj (node-r bst) <))))))
(defun bst-min (bst)
(and bst
(or (bst-min (node-l bst)) bst)))
(defun bst-max (bst)
(and bst
(or (bst-max (node-r bst)) bst)))
圖 4.5 二元搜索樹:查詢與插入
一棵二元搜索樹可以是 nil 或是一個左子、右子樹都是二元搜索樹的節點。如同列表可由連續呼叫 cons 來構造,二元搜索樹將可以通過連續呼叫 bst-insert 來構造。這個函數接受一個物件,一棵二元搜索樹及一個排序函數,並返回將物件插入的二元搜索樹。和 cons 函數一樣, bst-insert 不改動做爲第二個實參所傳入的二元搜索樹。以下是如何使用這個函數來構造一棵叉搜索樹:
> (setf nums nil)
NIL
> (dolist (x '(5 8 4 2 1 9 6 7 3))
(setf nums (bst-insert x nums #'<)))
NIL
圖 4.4 顯示了此時 nums 的結構所對應的樹。
我們可以使用 bst-find 來找到二元搜索樹中的物件,它與 bst-insert 接受同樣的參數。先前敘述所提到的 node 結構,它像是一個具有兩個 cdr 的 cons 核。如果我們把 16 頁的 our-member 拿來與 bst-find 比較的話,這樣的類比更加明確。
與 member 相同, bst-find 不僅返回要尋找的元素,也返回了用尋找元素做爲根節點的子樹:
> (bst-find 12 nums #'<)
NIL
> (bst-find 4 nums #'<)
#<4>
這使我們可以區分出無法找到某物,以及成功找到 nil 的情況。
要找到二元搜索樹的最小及最大的元素是很簡單的。要找到最小的,我們沿著左子樹的路徑走,如同 bst-min 所做的。要找到最大的,沿著右子樹的路徑走,如同 bst-max 所做的:
> (bst-min nums)
#<1>
> (bst-max nums)
#<9>
要從二元搜索樹裡移除元素一樣很快,但需要更多程式碼。圖 4.6 示範了如何從二元搜索樹裡移除元素。
(defun bst-remove (obj bst <)
(if (null bst)
nil
(let ((elt (node-elt bst)))
(if (eql obj elt)
(percolate bst)
(if (funcall < obj elt)
(make-node
:elt elt
:l (bst-remove obj (node-l bst) <)
:r (node-r bst))
(make-node
:elt elt
:r (bst-remove obj (node-r bst) <)
:l (node-l bst)))))))
(defun percolate (bst)
(cond ((null (node-l bst))
(if (null (node-r bst))
nil
(rperc bst)))
((null (node-r bst)) (lperc bst))
(t (if (zerop (random 2))
(lperc bst)
(rperc bst)))))
(defun rperc (bst)
(make-node :elt (node-elt (node-r bst))
:l (node-l bst)
:r (percolate (node-r bst))))
圖 4.6 二元搜索樹:移除
勘誤: 此版 bst-remove 的定義已被回報是壞掉的,請參考 這裡 獲得修復版。
函數 bst-remove 接受一個物件,一棵二元搜索樹以及排序函數,並返回一棵與本來的二元搜索樹相同的樹,但不包含那個要移除的物件。和 remove 一樣,它不改動做爲第二個實參所傳入的二元搜索樹:
> (setf nums (bst-remove 2 nums #'<))
#<5>
> (bst-find 2 nums #'<)
NIL
此時 nums 的結構應該如圖 4.7 所示。 (另一個可能性是 1 取代了 2 的位置。)
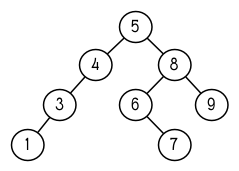
圖 4.7: 二元搜索樹
移除需要做更多工作,因爲從內部節點移除一個物件時,會留下一個空缺,需要由其中一個孩子來填補。這是 percolate 函數的用途。當它替換一個二元搜索樹的樹根(topmost element)時,會找其中一個孩子來替換,並用此孩子的孩子來填補,如此這般一直遞迴下去。
爲了要保持樹的平衡,如果有兩個孩子時, perlocate 隨機擇一替換。表達式 (random 2) 會返回 0 或 1 ,所以 (zerop (random 2)) 會返回真或假。
(defun bst-traverse (fn bst)
(when bst
(bst-traverse fn (node-l bst))
(funcall fn (node-elt bst))
(bst-traverse fn (node-r bst))))
圖 4.8 二元搜索樹:遍歷
一旦我們把一個物件集合插入至二元搜索樹時,中序遍歷會將它們由小至大排序。這是圖 4.8 中, bst-traverse 函數的用途:
> (bst-traverse #'princ nums)
13456789
NIL
(函數 princ 僅顯示單一物件)
本節所給出的程式,提供了一個二元搜索樹實現的腳手架。你可能想根據應用需求,來充實這個腳手架。舉例來說,這裡所給出的程式每個節點只有一個 elt 欄位;在許多應用裡,有兩個欄位會更有意義, key 與 value 。本章的這個版本把二元搜索樹視爲集合看待,從這個角度看,重複的插入是被忽略的。但是程式可以很簡單地改動,來處理重複的元素。
二元搜索樹不僅是維護一個已排序物件的集合的方法。他們是否是最好的方法,取決於你的應用。一般來說,二元搜索樹最適合用在插入與刪除是均勻分佈的情況。有一件二元搜索樹不擅長的事,就是用來維護優先佇列(priority queues)。在一個優先佇列裡,插入也許是均勻分佈的,但移除總是在一個另一端。這會導致一個二元搜索樹變得不平衡,而我們期望的複雜度是 O(log(n)) 插入與移除操作,將會變成 O(n) 。如果用二元搜索樹來表示一個優先佇列,也可以使用一般的列表,因爲二元搜索樹最終會作用的像是個列表。
4.8 雜湊表 (Hash Table)¶
第三章示範過列表可以用來表示集合(sets)與映射(mappings)。但當列表的長度大幅上升時(或是 10 個元素),使用雜湊表的速度比較快。你通過呼叫 make-hash-table 來構造一個雜湊表,它不需要傳入參數:
> (setf ht (make-hash-table))
#<Hash-Table BF0A96>
和函數一樣,雜湊表總是用 #<...> 的形式來顯示。
一個雜湊表,與一個關聯列表類似,是一種表達對應關係的方式。要取出與給定鍵值有關的數值,我們呼叫 gethash 並傳入一個鍵值與雜湊表。預設情況下,如果沒有與這個鍵值相關的數值, gethash 會返回 nil 。
> (gethash 'color ht)
NIL
NIL
在這裡我們首次看到 Common Lisp 最突出的特色之一:一個表達式竟然可以返回多個數值。函數 gethash 返回兩個數值。第一個值是與鍵值有關的數值,第二個值說明了雜湊表是否含有任何用此鍵值來儲存的數值。由於第二個值是 nil ,我們知道第一個 nil 是預設的返回值,而不是因爲 nil 是與 color 有關的數值。
大部分的實現會在頂層顯示一個函數呼叫的所有返回值,但僅期待一個返回值的程式,只會收到第一個返回值。 5.5 節會說明,程式如何接收多個返回值。
要把數值與鍵值作關聯,使用 gethash 搭配 setf :
> (setf (gethash 'color ht) 'red)
RED
現在如果我們再次呼叫 gethash ,我們會得到我們剛插入的值:
> (gethash 'color ht)
RED
T
第二個返回值證明,我們取得了一個真正儲存的物件,而不是預設值。
存在雜湊表的物件或鍵值可以是任何型別。舉例來說,如果我們要保留函數的某種訊息,我們可以使用雜湊表,用函數作爲鍵值,字串作爲詞條(entry):
> (setf bugs (make-hash-table))
#<Hash-Table BF4C36>
> (push "Doesn't take keyword arguments."
(gethash #'our-member bugs))
("Doesn't take keyword arguments.")
由於 gethash 預設返回 nil ,而 push 是 setf 的縮寫,可以輕鬆的給雜湊表新添一個詞條。 (有困擾的 our-member 定義在 16 頁。)
可以用雜湊表來取代用列表表示集合。當集合變大時,雜湊表的查詢與移除會來得比較快。要新增一個成員到用雜湊表所表示的集合,把 gethash 用 setf 設成 t :
> (setf fruit (make-hash-table))
#<Hash-Table BFDE76>
> (setf (gethash 'apricot fruit) t)
T
然後要測試是否爲成員,你只要呼叫:
> (gethash 'apricot fruit)
T
T
由於 gethash 預設返回真,一個新創的雜湊表,會很方便地是一個空集合。
要從集閤中移除一個物件,你可以呼叫 remhash ,它從一個雜湊表中移除一個詞條:
> (remhash 'apricot fruit)
T
返回值說明了是否有詞條被移除;在這個情況裡,有。
雜湊表有一個迭代函數: maphash ,它接受兩個實參,接受兩個參數的函以及雜湊表。該函數會被每個鍵值對呼叫,沒有特定的順序:
> (setf (gethash 'shape ht) 'spherical
(gethash 'size ht) 'giant)
GIANT
> (maphash #'(lambda (k v)
(format t "~A = ~A~%" k v))
ht)
SHAPE = SPHERICAL
SIZE = GIANT
COLOR = RED
NIL
maphash 總是返回 nil ,但你可以通過傳入一個會累積數值的函數,把雜湊表的詞條存在列表裡。
雜湊表可以容納任何數量的元素,但當雜湊表空間用完時,它們會被擴張。如果你想要確保一個雜湊表,從特定數量的元素空間大小開始時,可以給 make-hash-table 一個選擇性的 :size 關鍵字參數。做這件事情有兩個理由:因爲你知道雜湊表會變得很大,你想要避免擴張它;或是因爲你知道雜湊表會是很小,你不想要浪費記憶體。 :size 參數不僅指定了雜湊表的空間,也指定了元素的數量。平均來說,在被擴張前所能夠容納的數量。所以
(make-hash-table :size 5)
會返回一個預期存放五個元素的雜湊表。
和任何牽涉到查詢的結構一樣,雜湊表一定有某種比較鍵值的概念。預設是使用 eql ,但你可以提供一個額外的關鍵字參數 :test 來告訴雜湊表要使用 eq , equal ,還是 equalp :
> (setf writers (make-hash-table :test #'equal))
#<Hash-Table C005E6>
> (setf (gethash '(ralph waldo emerson) writers) t)
T
這是一個讓雜湊表變得有效率的取捨之一。有了列表,我們可以指定 member 爲判斷相等性的謂詞。有了雜湊表,我們可以預先決定,並在雜湊表構造時指定它。
大多數 Lisp 編程的取捨(或是生活,就此而論)都有這種特質。起初你想要事情進行得流暢,甚至賠上效率的代價。之後當程式變得沉重時,你犧牲了彈性來換取速度。
Chapter 4 總結 (Summary)¶
- Common Lisp 支援至少 7 個維度的陣列。一維陣列稱爲向量。
- 字串是字元的向量。字元本身就是物件。
- 序列包括了向量與列表。許多序列函數都接受標準的關鍵字參數。
- 處理字串的函數非常多,所以用 Lisp 來解析字串是小菜一碟。
- 呼叫
defstruct定義了一個帶有命名欄位的結構。它是一個程式能寫出程式的好例子。 - 二元搜索樹見長於維護一個已排序的物件集合。
- 雜湊表提供了一個更有效率的方式來表示集合與映射 (mappings)。
Chapter 4 習題 (Exercises)¶
- 定義一個函數,接受一個平方陣列(square array,一個相同維度的陣列
(n n)),並將它順時針轉 90 度。
> (quarter-turn #2A((a b) (c d)))
#2A((C A) (D B))
你會需要用到 361 頁的 array-dimensions 。
- 閱讀 368 頁的
reduce說明,然後用它來定義:
(a) copy-list
(b) reverse(針對列表)
- 定義一個結構來表示一棵樹,其中每個節點包含某些資料及三個小孩。定義:
(a) 一個函數來複製這樣的樹(複製完的節點與本來的節點是不相等( `eql` )的)
(b) 一個函數,接受一個物件與這樣的樹,如果物件與樹中各節點的其中一個欄位相等時,返回真。
- 定義一個函數,接受一棵二元搜索樹,並返回由此樹元素所組成的,一個由大至小排序的列表。
- 定義
bst-adjoin。這個函數應與bst-insert接受相同的參數,但應該只在物件不等於任何樹中物件時將其插入。
勘誤: bst-adjoin 的功能與 bst-insert 一模一樣。
- 任何雜湊表的內容可以由關聯列表(assoc-list)來描述,其中列表的元素是
(k . v)的形式,對應到雜湊表中的每一個鍵值對。定義一個函數:
(a) 接受一個關聯列表,並返回一個對應的雜湊表。
(b) 接受一個雜湊表,並返回一個對應的關聯列表。
腳註
| [1] | 一個簡單陣列大小是不可調整、元素也不可替換的,並不含有填充指標(fill-pointer)。陣列預設是簡單的。簡單向量是個一維的簡單陣列,可以含有任何型別的元素。 |
| [2] | 在 ANSI Common Lisp 裡,你可以給一個 :print-object 的關鍵字參數來取代,它只需要兩個實參。也有一個宏叫做 print-unreadable-object ,能用則用,可以用 #<...> 的語法來顯示物件。 |